38. PostgreSQL säkerhetskopiering och återställning¶
Det finns många sätt att säkerhetskopiera en PostgreSQL-databas, och den du väljer kommer att bero mycket på hur du använder databasen.
För relativt statiska databaser kan de grundläggande verktygen pg_dump/pg_restore användas för att ta periodiska ögonblicksbilder av data.
För data som ändras ofta kan man använda ett system med ”online backup” för att kontinuerligt arkivera uppdateringar på en säker plats.
Online backup är grunden för replikering och standby-system för hög tillgänglighet, särskilt för versioner av PostgreSQL >= 9.0.
38.1. Lägga ut dina data¶
Som diskuterades i PostgreSQL-scheman är det en mycket viktig best practice vid datahantering att se till att produktionsdata alltid lagras i separata scheman. Det finns två skäl till detta:
Det är mycket enklare att säkerhetskopiera och återställa data i scheman än att hantera listor med tabeller som ska säkerhetskopieras individuellt.
Genom att hålla datatabeller utanför det ”offentliga” schemat blir det mycket enklare att göra uppgraderingar, vilket diskuteras i Uppgraderingar av programvara.
38.2. Grundläggande säkerhetskopiering och återställning¶
Det är enkelt att säkerhetskopiera en hel databas med hjälp av verktyget pg_dump. Verktyget är ett kommandoradsverktyg, vilket gör det enkelt att automatisera med skript, och det kan också anropas via ett GUI i verktyget PgAdmin.
För att säkerhetskopiera vår nyc-databas kan vi använda GUI, högerklicka bara på den databas du vill säkerhetskopiera:
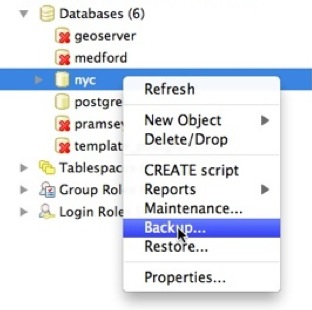
Ange namnet på den backup-fil som du vill skapa.
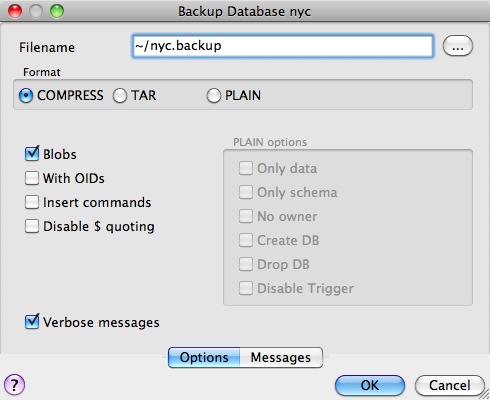
Observera att det finns tre alternativ för säkerhetskopieringsformat: compress, tar och plain.
Plain är bara en textuell SQL-fil. Detta är det enklaste formatet och på många sätt det mest flexibla, eftersom det enkelt kan redigeras eller ändras och sedan laddas tillbaka till en databas, vilket möjliggör offlineändringar av saker som ägande eller annan global information.
Tar använder ett UNIX-arkivformat för att hålla komponenter i dumpningen i separata filer. Genom att använda tar-formatet kan verktyget pg_restore selektivt återställa delar av dumpen.
Compress är som Tar-formatet, men komprimerar de interna komponenterna individuellt, vilket gör att de kan återställas selektivt utan att hela arkivet behöver dekomprimeras.
Vi markerar alternativet Komprimera och sparar en backup-fil.
Samma operation kan göras med kommandoraden på följande sätt:
pg_dump --file=nyc.backup --format=c --port=54321 --username=postgres nyc
Eftersom säkerhetskopian är i Compress-format kan vi visa innehållet med hjälp av kommandot pg_restore för att lista manifestet. I PgAdmin GUI är ”View” ett alternativ i panelen.

När du tittar på manifestet kanske du märker att det finns många ”FUNCTION”-signaturer där.
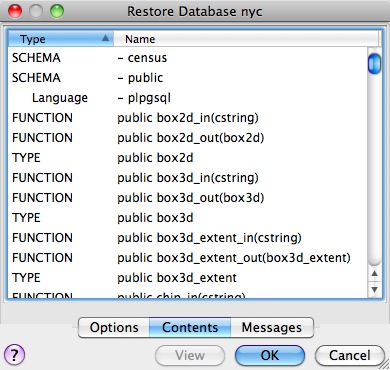
Det beror på att verktyget pg_dump dumpar alla icke-systemobjekt i databasen, och det inkluderar PostGIS-funktionsdefinitionerna.
Observera
PostgreSQL 9.1+ innehåller en ”EXTENSION” -funktion som gör att tilläggspaket som PostGIS kan installeras som registrerade systemkomponenter och därför utesluts från pg_dump-utdata. PostGIS 2.0 och högre stöder installation med hjälp av detta förlängningssystem.
Vi kan se samma manifest från kommandoraden med hjälp av pg_restore direkt:
pg_restore --list nyc.backup
Problemet med en dumpfil full av PostGIS-funktionssignaturer är att vi egentligen ville ha en dump av våra data, inte av våra systemfunktioner.
Eftersom varje objekt finns i dumpfilen kan vi återställa till en tom databas och få full funktionalitet. När vi gör det förväntar vi oss att det system vi återställer till har exakt samma version av PostGIS som det vi dumpade från (eftersom funktionssignaturdefinitionerna hänvisar till en viss version av det delade biblioteket PostGIS).
Från kommandoraden ser återställningen ut så här:
createdb --port 54321 nyc2
pg_restore --dbname=nyc2 --port 54321 --username=postgres nyc.backup
Att bara dumpa data utan funktionssignaturer är praktiskt eftersom det finns en kommandoradsflagga som gör att man bara kan dumpa ett visst schema:
pg_dump --port=54321 -format=c --schema=census --file=census.backup
När vi nu listar innehållet i dumpningen ser vi precis de datatabeller vi ville ha:
pg_restore --list census.backup
;
; Archive created at Thu Aug 9 11:02:49 2012
; dbname: nyc
; TOC Entries: 11
; Compression: -1
; Dump Version: 1.11-0
; Format: CUSTOM
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 8.4.9
; Dumped by pg_dump version: 8.4.9
;
;
; Selected TOC Entries:
;
6; 2615 20091 SCHEMA - census postgres
146; 1259 19845 TABLE census nyc_census_blocks postgres
145; 1259 19843 SEQUENCE census nyc_census_blocks_gid_seq postgres
2691; 0 0 SEQUENCE OWNED BY census nyc_census_blocks_gid_seq postgres
2692; 0 0 SEQUENCE SET census nyc_census_blocks_gid_seq postgres
2681; 2604 19848 DEFAULT census gid postgres
2688; 0 19845 TABLE DATA census nyc_census_blocks postgres
2686; 2606 19853 CONSTRAINT census nyc_census_blocks_pkey postgres
2687; 1259 20078 INDEX census nyc_census_blocks_geom_gist postgres
Det är praktiskt att bara ha datatabellerna, eftersom det innebär att vi kan lagra i en databas med vilken version av PostGIS som helst installerad, som vi talar om i Uppgraderingar av programvara.
38.2.1. Säkerhetskopiera användare¶
Verktyget pg_dump hanterar en databas åt gången (eller ett schema eller en tabell åt gången, om du begränsar det). Information om användare lagras dock över ett helt kluster, den lagras inte i någon enskild databas!
För att säkerhetskopiera din användarinformation använder du verktyget pg_dumpall med flaggan ”–globals-only”.
pg_dumpall --globals-only --port 54321
Du kan också använda pg_dumpall i dess standardläge för att säkerhetskopiera ett helt kluster, men tänk på att du, precis som med pg_dump, kommer att säkerhetskopiera PostGIS-funktionssignaturerna, så dumpen måste återställas mot en identisk programvaruinstallation, den kan inte användas som en del av en uppgraderingsprocess.
38.3. Online backup och återställning¶
Online backup och återställning gör det möjligt för en administratör att hålla en extremt uppdaterad uppsättning backupfiler utan att behöva dumpa hela databasen upprepade gånger. Om databasen ofta utsätts för inmatningar och uppdateringar kan onlinebackup vara att föredra framför grundläggande backup.
Observera
Det bästa sättet att lära sig om säkerhetskopiering online är att läsa relevanta avsnitt i PostgreSQL-manualen om kontinuerlig arkivering och återställning av punkt i tid. Det här avsnittet i PostGIS-workshopen kommer bara att ge en kort ögonblicksbild av online-säkerhetskopiering.
38.3.1. Hur det fungerar¶
I stället för att kontinuerligt skriva till huvuddatatabellerna lagrar PostgreSQL ändringar initialt i ”write-ahead logs” (WAL). Sammantaget är dessa loggar en fullständig registrering av alla ändringar som gjorts i en databas. Onlinebackup består av att ta en kopia av databasens huvuddatatabell och sedan ta en kopia av varje WAL som genereras från och med då.
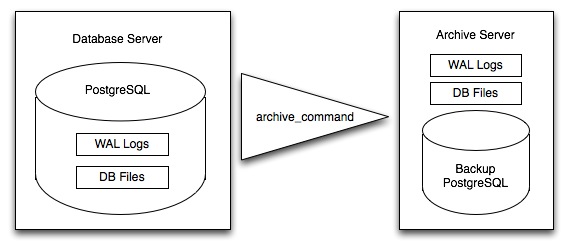
När det är dags att återställa till en ny databas startar systemet på huvuddatakopian och spelar sedan in alla WAL-filer i databasen. Slutresultatet är en återställd databas i samma skick som originalet vid tidpunkten för den senast mottagna WAL-filen.
Eftersom WAL skrivs ändå och det är billigt att överföra kopior till en arkivserver är onlinebackup ett effektivt sätt att hålla en mycket aktuell backup av ett system utan att behöva använda intensiva regelbundna fulldumps.
38.3.2. Arkivering av WAL-filer¶
Det första du ska göra för att ställa in säkerhetskopiering online är att skapa en arkiveringsmetod. PostgreSQL-arkiveringsmetoder är det ultimata i flexibilitet: PostgreSQL-backend anropar helt enkelt ett skript som anges i konfigurationsparametern archive_command.
Det innebär att arkivering kan vara så enkelt som att kopiera filen till en nätverksmonterad enhet, och så komplext som att kryptera och e-posta filerna till fjärrarkivet. Alla processer som du kan skripta kan du använda för att arkivera filerna.
För att slå på arkivering ska vi redigera postgresql.conf och först slå på WAL-arkivering:
wal_level = archive
archive_mode = on
Och sedan ställa in archive_command för att kopiera våra arkivfiler till en säker plats (ändra destinationssökvägarna efter behov):
# Unix
archive_command = 'test ! -f /archivedir/%f && cp %p /archivedir/%f'
# Windows
archive_command = 'copy "%p" "C:\\archivedir\\%f"'
Det är viktigt att arkivkommandot inte skriver över befintliga filer, så unix-kommandot innehåller ett första test för att säkerställa att filerna inte redan finns där. Det är också viktigt att kommandot returnerar en status som inte är noll om kopieringsprocessen misslyckas.
När ändringarna har gjorts kan du starta om PostgreSQL för att göra dem effektiva.
38.3.3. Ta backup av basen¶
När arkiveringsprocessen är på plats måste du ta en grundläggande säkerhetskopia.
Sätt databasen i säkerhetskopieringsläge (detta gör ingenting för att ändra driften av frågor eller datauppdateringar, det tvingar bara fram en kontrollpunkt och skriver en etikettfil som anger när säkerhetskopian togs).
SELECT pg_start_backup('/archivedir/basebackup.tgz');
För etiketten är det en bra metod att använda sökvägen till säkerhetskopian, eftersom det hjälper dig att spåra var säkerhetskopian lagrades.
Kopiera databasen till en arkiveringsplats:
# Unix
tar cvfz /archivedir/basebackup.tgz ${PGDATA}
Meddela sedan databasen att säkerhetskopieringen är slutförd.
SELECT pg_stop_backup();
Alla dessa steg kan naturligtvis skriptas för regelbundna säkerhetskopieringar.
38.3.4. Återställning från arkivet¶
Dessa steg tas från PostgreSQL-manualen om kontinuerlig arkivering och återställning av punkt i tid.
Stoppa servern, om den är igång.
Om du har utrymme för det kan du kopiera hela datakatalogen för klustret och alla tablespaces till en tillfällig plats om du behöver dem senare. Observera att denna försiktighetsåtgärd kräver att du har tillräckligt med ledigt utrymme på ditt system för att hålla två kopior av din befintliga databas. Om du inte har tillräckligt med utrymme bör du åtminstone spara innehållet i klustrets underkatalog pg_xlog, eftersom den kan innehålla loggar som inte arkiverades innan systemet gick ner.
Ta bort alla befintliga filer och underkataloger under klusterdatakatalogen och under rotkatalogerna för alla tablespaces som du använder.
Återställ databasfilerna från din säkerhetskopia av filsystemet. Se till att de återställs med rätt ägarskap (databassystemets användare, inte root!) och med rätt behörigheter. Om du använder tablespaces bör du kontrollera att de symboliska länkarna i pg_tblspc/ har återställts korrekt.
Ta bort alla filer som finns i pg_xlog/; dessa kom från säkerhetskopian av filsystemet och är därför förmodligen föråldrade snarare än aktuella. Om du inte arkiverade pg_xlog/ alls, återskapa den med korrekta behörigheter och var noga med att se till att du återskapar den som en symbolisk länk om du hade konfigurerat den på det sättet tidigare.
Om du har oarkiverade WAL-segmentfiler som du sparade i steg 2, kopiera dem till pg_xlog/. (Det är bäst att kopiera dem, inte flytta dem, så att du fortfarande har de omodifierade filerna om ett problem uppstår och du måste börja om)
Skapa en kommandofil för återställning, recovery.conf, i klustrets datakatalog (se kapitel 26). Du kanske också vill ändra pg_hba.conf tillfälligt för att hindra vanliga användare från att ansluta tills du är säker på att återställningen har lyckats.
Starta servern. Servern går in i återställningsläge och fortsätter att läsa igenom de arkiverade WAL-filer som den behöver. Om återställningen skulle avbrytas på grund av ett externt fel kan servern helt enkelt startas om så fortsätter återställningen. När återställningsprocessen har slutförts byter servern namn på recovery.conf till recovery.done (för att förhindra att återställningsläget av misstag återinförs senare) och påbörjar sedan normal databasdrift.
Kontrollera innehållet i databasen för att säkerställa att du har återställt till önskat tillstånd. Om inte, återgå till steg 1. Om allt är bra kan du låta dina användare ansluta genom att återställa pg_hba.conf till det normala.
