27. Klustring på index¶
Databaser kan bara hämta information så snabbt som de kan få ut den från disken. Små databaser flyter helt upp i RAM-cache och slipper fysiska diskbegränsningar, men för stora databaser kommer åtkomsten till den fysiska disken att vara ett begränsande stopp i diskåtkomsthastigheten.
Data skrivs till disken på ett opportunistiskt sätt, så det finns inte nödvändigtvis någon korrelation mellan den ordning data lagras på disken och hur de kommer att användas eller organiseras av programmen.
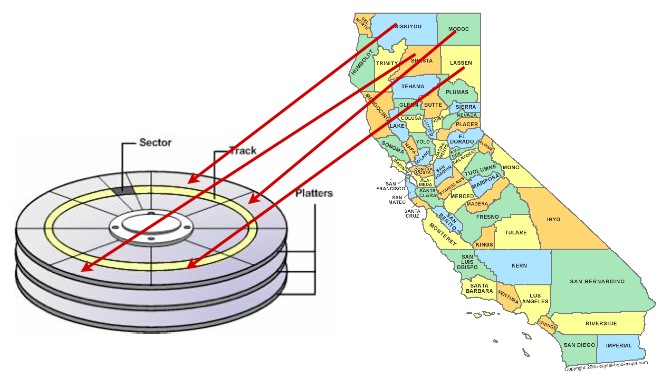
Ett sätt att snabba upp åtkomsten till data är att se till att poster som sannolikt kommer att hämtas tillsammans i samma resultatmängd finns på liknande fysiska platser på hårddiskplattorna. Detta kallas ”klustring”.
Det kan vara svårt att välja rätt klustringsschema, men en allmän regel gäller: index definierar ett naturligt ordningsschema för data som liknar det åtkomstmönster som kommer att användas vid hämtning av data.
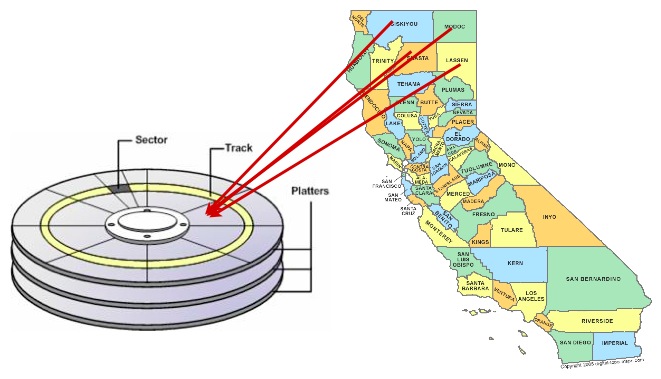
Därför kan det i vissa fall ge en hastighetsfördel att ordna data på disken i samma ordning som indexet.
27.1. Klustring på R-trädet¶
Spatial data tenderar att nås i spatialt korrelerade fönster: tänk på kartfönstret i en webb- eller skrivbordsapplikation. Alla data i fönstren har liknande platsvärde (annars skulle de inte finnas i fönstret!)
Klustring baserad på ett spatialt index är därför meningsfullt för spatiala data som kommer att nås med spatiala frågor: liknande saker tenderar att ha liknande platser.
Låt oss klustra våra nyc_census_block baserat på deras spatiala index:
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
Kommandot skriver om nyc_census_blocks i den ordning som definieras av det spatiala indexet nyc_census_blocks_geom_gist. Kan du se någon hastighetsskillnad? Kanske inte, eftersom originaldata redan kan ha haft en viss befintlig spatial ordning (detta är inte ovanligt i GIS-datauppsättningar).
27.2. Disk jämfört med minne/SSD¶
De flesta moderna databaser körs med SSD-lagring, som är mycket snabbare vid slumpmässig åtkomst än gamla roterande magnetiska medier. Dessutom körs de flesta moderna databaser på data som är tillräckligt små för att rymmas i databasserverns RAM-minne och som hamnar där när operativsystemets ”virtuella filsystem” lagrar dem i cacheminnet.
Är klustring fortfarande nödvändigt?
Surprisingly, yes. Keeping records that are ”near each other” in space ”near each other” in memory increases the odds that related records will move up the servers ”memory cache hierarchy” together, and thus make memory accesses faster.
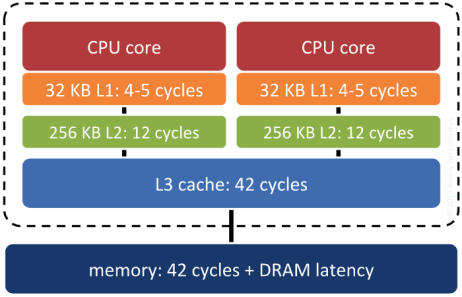
System RAM is not the fastest memory on a modern computer. There are several levels of cache between system RAM and the actual CPU, and the underlying operating system and processor will move data up and down the cache hierarchy in blocks. If the block getting moved up happens to include the piece of data the system will need next… that’s a big win. Correlating the memory structure with the spatial structure is a way in increase the odds of that win happening.
27.3. Har indexstrukturen någon betydelse?¶
I teorin, ja. I praktiken inte riktigt. Så länge indexet är en ”ganska bra” spatial nedbrytning av data kommer den viktigaste faktorn för prestanda att vara ordningen på de faktiska tabelltuplerna.
Skillnaden mellan ”inget index” och ”index” är i allmänhet enorm och mycket mätbar. Skillnaden mellan ”mediokert index” och ”bra index” kräver vanligtvis ganska noggranna mätningar för att urskiljas och kan vara mycket känslig för den arbetsbelastning som testas.
27.4. Funktionslista¶
CLUSTER: Ordnar om data i en tabell så att de stämmer överens med ordningen i indexet.
