15. Spatial indexering¶
Kom ihåg att ett spatialt index är en av de tre viktigaste egenskaperna hos en spatial databas. Index gör det möjligt att använda en spatial databas för stora datamängder. Utan indexering skulle varje sökning efter en funktion kräva en ”sekventiell skanning” av varje post i databasen. Indexering påskyndar sökningen genom att data organiseras i ett sökträd som snabbt kan genomgås för att hitta en viss post.
Spatiala index är en av de största tillgångarna i PostGIS. I det föregående exemplet krävdes det att hela tabeller jämfördes med varandra för att skapa spatiala sammankopplingar. Detta kan bli mycket kostsamt: att sammanfoga två tabeller med 10 000 poster vardera utan index skulle kräva 100 000 000 000 jämförelser; med index kan kostnaden bli så låg som 20 000 jämförelser.
Vår dataladdningsfil innehöll redan spatiala index för alla tabeller, så för att kunna visa indexens effektivitet måste vi först ta bort dem.
Låt oss köra en fråga på nyc_census_blocks utan vårt spatiala index.
Vårt första steg är att ta bort indexet.
DROP INDEX nyc_census_blocks_geom_idx;
Observera
Uttalandet DROP INDEX tappar ett befintligt index från databassystemet. För mer information, se PostgreSQL-dokumentationen <http://www.postgresql.org/docs/current/interactive/sql-dropindex.html>`_.
Titta nu på ”Timing”-mätaren i det nedre högra hörnet av pgAdmin-frågefönstret och kör följande. Vår fråga söker igenom varje enskilt folkbokföringsblock för att identifiera block som innehåller tunnelbanestationer som börjar med ”B”.
SELECT count(blocks.blkid)
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name LIKE 'B%';
count
---------------
46
Tabellen nyc_census_blocks är mycket liten (bara några tusen poster) så även utan ett index tar frågan bara 300 ms på min testdator.
Lägg nu till det spatiala indexet igen och kör frågan igen.
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocks
USING GIST (geom);
Observera
Klausulen USING GIST säger till PostgreSQL att använda den generiska indexstrukturen (GIST) när man bygger indexet. Om du får ett fel som ser ut som FEL: indexrad kräver 11340 byte, maximal storlek är 8191 när du skapar ditt index, har du sannolikt försummat att lägga till klausulen USING GIST.
På min testdator sjönk tiden till 50 ms. Ju större tabell du har, desto större blir den relativa hastighetsförbättringen av en indexerad fråga.
15.1. Hur spatiala index fungerar¶
Standarddatabasindex skapar ett hierarkiskt träd baserat på värdena i den kolumn som indexeras. Spatiala index är lite annorlunda - de kan inte indexera själva de geometriska objekten utan indexerar i stället objektens avgränsande boxar.
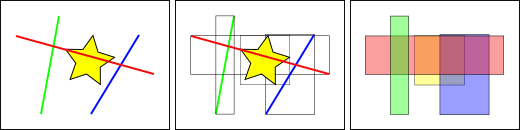
I figuren ovan är antalet linjer som korsar den gula stjärnan en, den röda linjen. Men de avgränsande rutorna för funktioner som skär den gula rutan är två, den röda och den blå.
Det sätt på vilket databasen effektivt besvarar frågan ”vilka linjer skär den gula stjärnan” är att först besvara frågan ”vilka rutor skär den gula rutan” med hjälp av indexet (vilket är mycket snabbt) och sedan göra en exakt beräkning av ”vilka linjer skär den gula stjärnan” endast för de funktioner som det första testet gav.
För en stor tabell kan detta ”tvåpass”-system, där man först utvärderar det approximativa indexet och sedan utför ett exakt test, radikalt minska antalet beräkningar som krävs för att besvara en fråga.
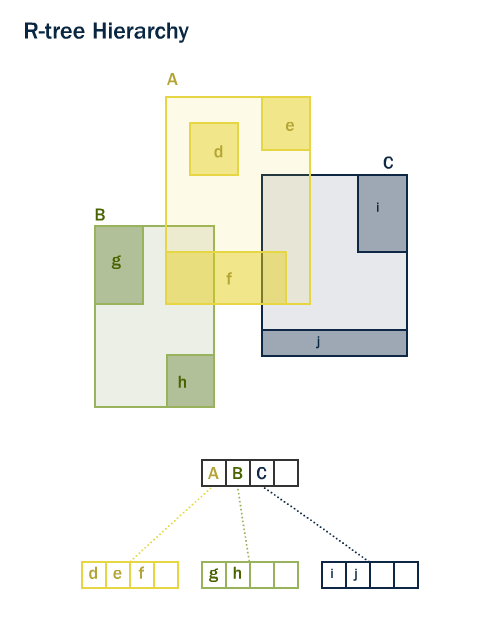
Både PostGIS och Oracle Spatial delar samma spatiala indexstruktur ”R-Tree” [1]. R-Trees delar upp data i rektanglar och subrektanglar och sub-sub-rektanglar osv. Det är en självjusterande indexstruktur som automatiskt hanterar varierande datatäthet, olika mängder objektöverlappning och objektstorlek.
15.2. Spatialt indexerade funktioner¶
Endast en del av funktionerna kommer automatiskt att använda ett spatialt index, om ett sådant finns tillgängligt.
De fyra första är de som oftast används i frågor, och ST_DWithin är mycket viktigt för att göra frågor av typen ”inom ett avstånd” eller ”inom en radie” och samtidigt få en prestandaförbättring från indexet.
För att lägga till indexacceleration till andra funktioner som inte finns i den här listan (oftast ST_Relate), lägg till en index-only-klausul enligt beskrivningen nedan.
15.3. Frågor med enbart index¶
De flesta av de vanligaste funktionerna i PostGIS (ST_Contains, ST_Intersects, ST_DWithin, etc) inkluderar ett indexfilter automatiskt. Men vissa funktioner (t.ex. ST_Relate) innehåller inte ett indexfilter.
För att göra en bounding-box-sökning med hjälp av indexet (och utan filtrering) använder du operatorn &&. För geometrier betyder operatorn && ”bounding boxes överlappar eller rör vid varandra” på samma sätt som operatorn = för tal betyder ”värdena är desamma”.
Låt oss jämföra en indexfråga för befolkningen i ”West Village” med en mer exakt fråga. Med hjälp av && ser vår indexfråga ut som följer:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
49821
Låt oss nu göra samma fråga med hjälp av den mer exakta funktionen ST_Intersects.
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
26718
Ett mycket lägre svar! Den första frågan summerade varje kvarter vars begränsningsbox skär grannskapets begränsningsbox; den andra frågan summerade bara de kvarter som skär själva grannskapet.
15.4. Analysering¶
PostgreSQL-frågeplaneraren väljer intelligent när man ska använda eller inte använda index för att utvärdera en fråga. Motintuitivt är det inte alltid snabbare att göra en indexsökning: om sökningen kommer att returnera varje post i tabellen, kommer det faktiskt att vara långsammare att korsa indexträdet för att få varje post än att bara sekventiellt läsa hela tabellen från början.
Att känna till storleken på frågerektangeln räcker inte för att avgöra om en fråga kommer att returnera ett stort antal eller ett litet antal poster. Nedan är den röda kvadraten liten, men kommer att returnera många fler poster än den blå kvadraten.
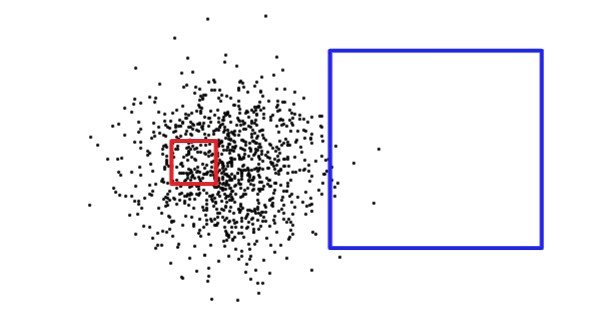
För att ta reda på vilken situation den har att göra med (läsa en liten del av tabellen jämfört med att läsa en stor del av tabellen) håller PostgreSQL statistik om fördelningen av data i varje indexerad tabellkolumn. Som standard samlar PostgreSQL statistik regelbundet. Men om du dramatiskt ändrar innehållet i din tabell inom en kort tidsperiod kommer statistiken inte att vara uppdaterad.
För att säkerställa att statistiken stämmer överens med tabellinnehållet är det klokt att köra kommandot ANALYZE efter massinläsning och radering av data i tabellerna. Detta tvingar statistiksystemet att samla in data för alla dina indexerade kolumner.
Kommandot ANALYZE ber PostgreSQL att korsa tabellen och uppdatera dess interna statistik som används för uppskattning av frågeplan (frågeplananalys kommer att diskuteras senare).
ANALYZE nyc_census_blocks;
15.5. Vacuuming¶
Det är värt att betona att det inte räcker att bara skapa ett index för att PostgreSQL ska kunna använda det effektivt. VACUUMING måste utföras när ett stort antal UPDATEs, INSERTs eller DELETEs utfärdas mot en tabell. Kommandot VACUUM ber PostgreSQL att återta allt oanvänt utrymme på tabellsidorna som lämnas av uppdateringar eller raderingar till poster.
Vacuuming är så viktigt för en effektiv körning av databasen att PostgreSQL tillhandahåller en ”autovacuum” -facilitet som standard.
Autovacuum både dammsuger (återställer utrymme) och analyserar (uppdaterar statistik) dina tabeller med förnuftiga intervall som bestäms av aktivitetsnivån. Även om detta är viktigt för databaser med många transaktioner, är det inte tillrådligt att vänta på en autovacuum-körning efter att ha lagt till index eller laddat upp data. Varje gång en stor batchuppdatering utförs bör du manuellt köra VACUUM.
Vacuuming och analys av databasen kan utföras separat efter behov. Kommandot VACUUM uppdaterar inte databasstatistiken, och kommandot ANALYZE återställer inte heller oanvända tabellrader. Båda kommandona kan köras mot hela databasen, en enstaka tabell eller en enstaka kolumn.
VACUUM ANALYZE nyc_census_blocks;
15.6. Funktionslista¶
geometry_a && geometry_b: Returnerar SANT om A:s avgränsande box överlappar B:s.
geometry_a = geometry_b: Före PostGIS 2.4 returnerar true om A:s bounding box är densamma som B:s. Från 2.4 och framåt Returnerar SANT endast om A:s geometri är densamma som B:s.
geometry_a ~= geometry_b: Returnerar SANT om A:s avgränsande box är lika med B:s avgränsande box.
ST_Intersects(geometry_a, geometry_b): Returnerar TRUE om geometrierna/geografin ”spatialt korsar varandra” - (delar någon del av utrymmet) och FALSE om de inte gör det (de är disjunkta).
Fotnoter
