22. Fler spatiala sammanfogningar¶
I förra avsnittet såg vi funktionerna ST_Centroid(geometry) och ST_Union([geometry]), och några enkla exempel. I det här avsnittet ska vi göra lite mer avancerade saker med dem.
22.1. Skapa en tabell över folkräkningsområden¶
I workshoppens katalog ”data” finns en fil som innehåller attributdata, men ingen geometri, ”NYC_census_sociodata.sql”. Tabellen innehåller intressanta socioekonomiska data om New York: pendlingstider, inkomster och utbildningsnivå. Det finns bara ett problem. Uppgifterna sammanfattas av ”census tract” och vi har inga spatiala data för census tract!
I detta avsnitt kommer vi att
Läs in tabellen
nyc_census_sociodata.sqlSkapa en spatial tabell för folkräkningstrakter
Koppla attributdata till spatiala data
Genomföra en analys med hjälp av våra nya data
22.1.1. Läser in nyc_census_sociodata.sql¶
Öppna SQL-frågefönstret i PgAdmin
Välj File->Open från menyn och bläddra till filen
nyc_census_sociodata.sqlTryck på knappen ”Run Query” (Kör fråga)
Om du trycker på knappen ”Uppdatera” i PgAdmin bör listan över tabeller nu innehålla tabellen
nyc_census_sociodata
22.1.2. Skapa en tabell över folkräkningsområden¶
Som vi såg i föregående avsnitt kan vi bygga upp geometrier på högre nivå från folkräkningsblocket genom att sammanfatta delsträngar av nyckeln blkid. För att få census tracts måste vi sammanfatta grupperingen på de första 11 tecknen i blkid.
360610001001001 = 36 061 000100 1 001
36 = State of New York
061 = New York County (Manhattan)
000100 = Census Tract
1 = Census Block Group
001 = Census Block
Skapa den nya tabellen med hjälp av aggregatet ST_Union:
-- Make the tracts table
CREATE TABLE nyc_census_tract_geoms AS
SELECT
ST_Union(geom) AS geom,
SubStr(blkid,1,11) AS tractid
FROM nyc_census_blocks
GROUP BY tractid;
-- Index the tractid
CREATE INDEX nyc_census_tract_geoms_tractid_idx
ON nyc_census_tract_geoms (tractid);
22.1.3. Koppla attributen till de spatiala data¶
Anslut tabellen över traktgeometrier till tabellen över traktattribut med en standardattributanslutning
-- Make the tracts table
CREATE TABLE nyc_census_tracts AS
SELECT
g.geom,
a.*
FROM nyc_census_tract_geoms g
JOIN nyc_census_sociodata a
ON g.tractid = a.tractid;
-- Index the geometries
CREATE INDEX nyc_census_tract_gidx
ON nyc_census_tracts USING GIST (geom);
22.1.4. Svara på en intressant fråga¶
Svara på en intressant fråga! ”Lista de 10 bästa stadsdelarna i New York ordnade efter andelen människor som har en akademisk examen.”
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Intersects(n.geom, t.geom)
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Vi sammanfattar den statistik vi är intresserade av och delar sedan upp den i slutet. För att undvika dividera med noll-fel bryr vi oss inte om att ta med områden som har ett befolkningsantal på noll.
graduate_pct | name | boroname
--------------+-------------------+-----------
47.6 | Carnegie Hill | Manhattan
42.2 | Upper West Side | Manhattan
41.1 | Battery Park | Manhattan
39.6 | Flatbush | Brooklyn
39.3 | Tribeca | Manhattan
39.2 | North Sutton Area | Manhattan
38.7 | Greenwich Village | Manhattan
38.6 | Upper East Side | Manhattan
37.9 | Murray Hill | Manhattan
37.4 | Central Park | Manhattan
Observera
New York-geografer kommer att undra över närvaron av ”Flatbush” i denna lista över överutbildade stadsdelar. Svaret diskuteras i nästa avsnitt.
22.2. Polygon/Polygon Joins¶
I vår intressanta fråga (i Svara på en intressant fråga) använde vi funktionen ST_Intersects(geometry_a, geometry_b) för att avgöra vilka polygoner för folkbokföringstrakter som skulle ingå i varje grannskapssammanfattning. Vilket leder till frågan: Vad händer om en trakt faller på gränsen mellan två stadsdelar? Den kommer att korsa båda, och kommer därför att ingå i den sammanfattande statistiken för båda.
För att undvika denna typ av dubbelräkning finns det två metoder:
Den enkla metoden är att se till att varje trakt bara faller inom ett sammanfattningsområde (med hjälp av ST_Centroid(geometry))
Den komplexa metoden är att dela upp korsande trakter vid gränserna (med ST_Intersection(geometry,geometry))
Här är ett exempel på hur vi använder den enkla metoden för att undvika dubbelräkning i vår fråga om forskarutbildning:
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Contains(n.geom, ST_Centroid(t.geom))
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Observera att det tar längre tid att köra frågan nu, eftersom funktionen ST_Centroid måste köras på varje folkräkningstrakt.
graduate_pct | name | boroname
--------------+---------------------+-----------
48.0 | Carnegie Hill | Manhattan
44.2 | Morningside Heights | Manhattan
42.1 | Greenwich Village | Manhattan
42.0 | Upper West Side | Manhattan
41.4 | Tribeca | Manhattan
40.7 | Battery Park | Manhattan
39.5 | Upper East Side | Manhattan
39.3 | North Sutton Area | Manhattan
37.4 | Cobble Hill | Brooklyn
37.4 | Murray Hill | Manhattan
Att undvika dubbelräkning förändrar resultatet!
22.2.1. Flatbush, då?¶
I synnerhet har Flatbush-kvarteret tappat från listan. Anledningen till detta kan man se genom att titta närmare på kartan över stadsdelen Flatbush i vår tabell.
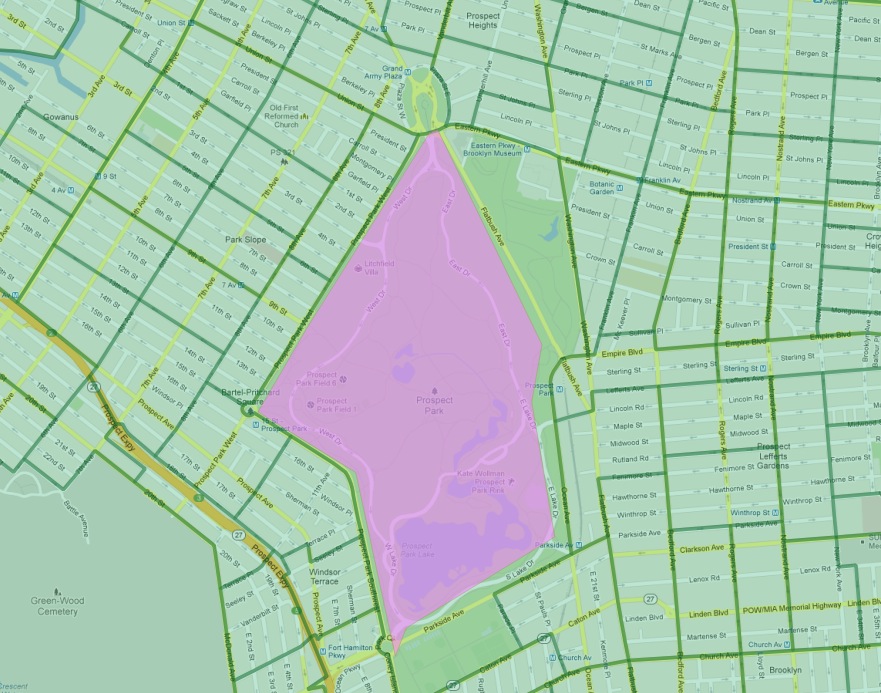
Enligt definitionen i vår datakälla är Flatbush egentligen inte en stadsdel i konventionell mening, eftersom den bara omfattar området Prospect Park. Folkräkningstrakten för det området registrerar naturligtvis noll invånare. Grannskapsgränsen skrapar dock ett av de dyra folkräkningstrakterna som gränsar till norra sidan av parken (i det gentrifierade Park Slope-området). När man använde polygon/polygontester lades denna enstaka trakt till det annars tomma Flatbush, vilket resulterade i den mycket höga poängen för den frågan.
22.3. Förband med stort radieavstånd¶
En fråga som är rolig att ställa är ”Hur skiljer sig pendlingstiderna för människor nära (inom 500 meter) tunnelbanestationer från dem för människor långt bort från tunnelbanestationer?”
Frågan stöter dock på vissa problem med dubbelräkning: många människor kommer att befinna sig inom 500 meter från flera tunnelbanestationer. Jämför befolkningen i New York:
SELECT Sum(popn_total)
FROM nyc_census_blocks;
8175032
Med befolkningen i New York inom 500 meter från en tunnelbanestation:
SELECT Sum(popn_total)
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500);
10855873
Det finns fler människor nära tunnelbanan än det finns människor! Det är uppenbart att vår enkla SQL gör ett stort dubbelräkningsfel. Du kan se problemet när du tittar på bilden av de buffrade tunnelbanorna.
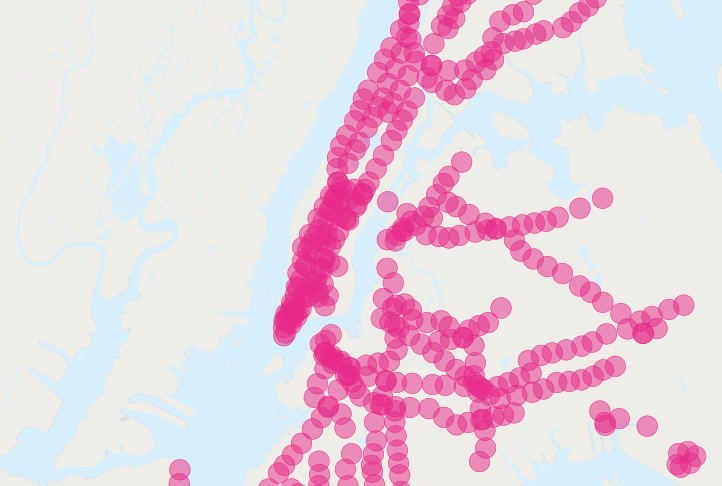
Lösningen är att se till att vi bara har distinkta folkräkningsblock innan vi skickar dem till sammanfattningsdelen av frågan. Vi kan göra det genom att bryta upp vår fråga i en underfråga som hittar de distinkta blocken, inslagna i en sammanfattningsfråga som returnerar vårt svar:
WITH distinct_blocks AS (
SELECT DISTINCT ON (blkid) popn_total
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500)
)
SELECT Sum(popn_total)
FROM distinct_blocks;
5005743
Det var bättre! Lite mer än hälften av New Yorks befolkning bor alltså inom 500 meter (cirka 5-7 minuters promenad) från tunnelbanan.
